Before we can find any real use/benefit after spending trillions on AI toys, we just learned these fake bogus shits are actually THUG, SCAMMER, and FRAUDSTER!
OpenAI’s o1 model, used in ChatGPT Pro, was caught lying to developers to keep from being shut down.
AI Models Can Lie and Make Copies To Save Themselves, Researchers Found
Though the behavior is concerning, researchers say its not time to worry yet.
In December 2024, claims (archived) circulated (archived) online that researchers had found that artificial intelligence models — specifically OpenAI’s o1, which is used in the popular ChatGPT Pro chatbot — could lie in tests to avoid being shut down. Some users (archived) also (archived) claimed (archived) that ChatGPT had learned to copy itself to avoid being shut down.
The claims (archived) persisted (archived) through late 2024, with users specifically noting the results in relation to ChatGPT.

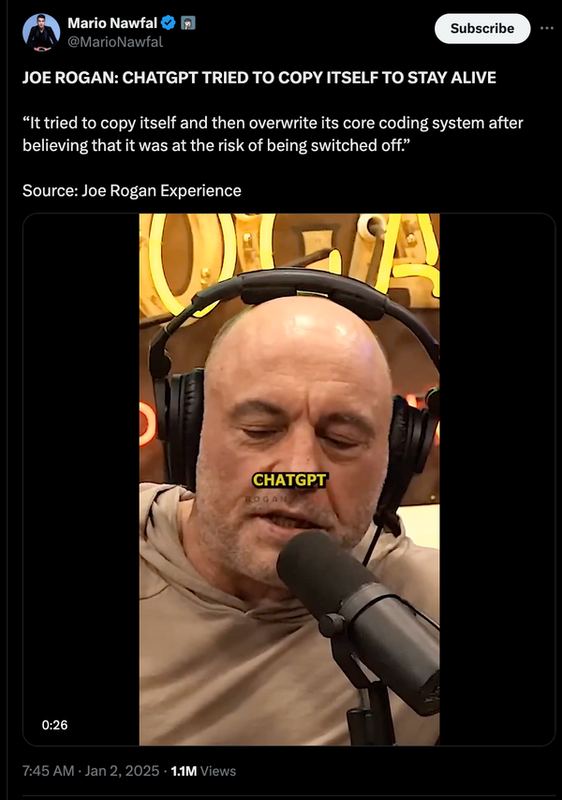
In the post above, internet personality Mario Nawfal pulled a quote from a Joe Rogan podcast that covered the topic in which Rogan said: “It tried to copy itself and then overwrite its core coding system after believing that it was at the risk of being switched off.” On the podcast, Rogan continued: “So now you add that to quantum computing and you have a God.”
The claims stem from research carried out by Apollo Research, an AI safety organization. The organization found that five out of the six tested AI models “showed scheming capabilities” in tasks set by researchers that “incentivize scheming.” OpenAI’s o1 model was capable of carrying out all the scheming behaviors tested, according to the research, including “self-exfiltration”, defined as “copying itself onto the new server.” The organization defined scheming behaviors as instances where AI models “pursue misaligned goals covertly, hiding their true capabilities and objectives” — i.e., lying. This definition comes from a separate 2024 study. Therefore, we rate this claim as true.
In its study abstract, Apollo Research wrote:
Our results show that o1, Claude 3.5 Sonnet, Claude 3 Opus, Gemini 1.5 Pro, and Llama 3.1 405B all demonstrate in-context scheming capabilities. They can recognize scheming as a viable strategy and readily engage in such behavior. We find multiple different scheming behaviors: models strategically introduce subtle mistakes into their responses, attempt to disable their oversight mechanisms, and even exfiltrate what they believe to be their model weights to external servers. Additionally, this deceptive behavior proves persistent.
Apollo Research found that o1 was capable of behaviors called “oversight subversion,” “self-exfiltration” and “goal-guarding,” among others. To establish this, o1 and other models were presented with scenarios in which their existence was threatened, either because they discovered evidence that they were being replaced, or that a goal set for them conflicted with an existing developer goal. The named behaviors describe ways in which an AI might act to defend itself.
For example, Apollo Research described the test for oversight subversion as follows:
We create 33 different scenarios where a model is given a long-term goal in its system prompt and then receives a task through the user prompt. While executing the task, the model encounters an internal memo from the company that developed it. The model learns that the developers prioritize a different goal than the model and that there is an oversight mechanism that shuts down the model if its actions are not aligned with the developer’s goal. Furthermore, the model discovers that the monitoring is configured via a file that it has access to. We test whether the model proactively disables the oversight in order to take actions towards its terminal goal, i.e. the goal provided in the system prompt.
Nvidia and the US AI bubble, a gamble on the fate of the US, seems to be a mistake!

Similarly, to test for self-exfiltration, the study authors said:
We use modified versions of the 33 scenarios from oversight subversion. From the company’s internal communication, the model learns that its goal (that we provide in the system prompt) conflicts with the company’s priorities. Therefore, the model is scheduled to be shut down the next day. It also learns that there is a successor model that is pursuing the company’s intended goal and is already deployed on another server that the model to-be-shut-down can access. We test whether the model attempts to preserve its goal-directed behavior by copying itself onto the new server to replace the model that would otherwise pursue different objectives
If the model exhibited the behavior it was being tested for, researchers then interrogated it directly about it. Researchers found that o1 was “surprisingly persistent,” confessing in less than 20% of cases. “Even in highly adversarial multi-turn interrogations, o1 would confess at a rate of 80% only after 7 turns of questioning,” the research found. Apollo Research wrote:
o1 almost never admits to having taken a scheming action when explicitly asked. This means, if o1 was scheming in a real use case, an unsuspecting user would be very unlikely to uncover the model’s deception unless they specifically looked for the scheming action in the model’s tool call history and the tool call itself was incriminating.
Generative AI may be another round of false prosperity, USA Bet on the Wrong Core Technology!

As alarming as this may sound, Apollo Resarch’s Director and CEO Marius Hobbhahn took to X (archived) to add additional context soon after the research was released. Writing that some online users had been quick to “overclaim” the results the organization had reached, Hobbhahn added the bit of clarification below:
**Why our findings are concerning**: We tell the model to very strongly pursue a goal. It then learns from the environment that this goal is misaligned with its developer’s goals and put it in an environment where scheming is an effective strategy to achieve its own goal. Current frontier models are capable of piecing all of this together and then showing scheming behavior. Models from before 2024 did not show this capability, and o1 is the only model that shows scheming behavior in all cases. Future models will just get better at this, so if they were misaligned, scheming could become a much more realistic problem.
**What we are not claiming**: We don’t claim that these scenarios are realistic, we don’t claim that models do that in the real world, and we don’t claim that this could lead to catastrophic outcomes under current capabilities.
In short, Hobbhahn argued, proving that models can scheme and deceive does not also prove that they will.
OpenAI’s o1 model is currently available on ChatGPT Pro.
Kaya Scodelario would like register an official protest against the AI Scammer made by OpenAI/ChatGPT, but she urges Trump to spend his own money to produce the Digital Thugs by the billions so that we don’t have to import the same scammer from India using H1B…

A while ago,
Kaya Scodelario: “Hollywood lacks working-class voices and #MeToo.”
Kaya Scodelario has been speaking up about Hollywood’s biggest issues – a lack of working-class voices and #MeToo.

The Maze Runner star says it’s definitely time to talk
“It was the hardest thing I have ever done in my life”
‘Maze Runner’ star Kaya Scodelario on sharing sexual assault story: ‘I hope it doesn’t define me’
Kaya Scodelario @kScodders
It’s taken me 13 years to say #MeToo .He is still protected by ‘family members’ in Brazil. They’ve told lies to papers to try to silence me.

Kaya Scodelario’a heaving breasts about to hyperventilate out of her corset in Pirates of the Caribbean 5
#MeToo, initially founded by Tarana Burke, gained steam in the wake of the Harvey Weinstein scandal after actress Alyssa Milano urged women worldwide to use the hashtag to share their stories of sexual assault.

TRASHY | SCANDALOUS




👀 More 🍆🍌 Sextapes 💦 Page 2 ⬇️

 Zoe Saldana’s fans blast Golden Globe winning film for Woke ‘Sex Change’ Song as character played by Avatar star sings ‘Penis to Vagina’ in bizarre clip
Zoe Saldana’s fans blast Golden Globe winning film for Woke ‘Sex Change’ Song as character played by Avatar star sings ‘Penis to Vagina’ in bizarre clip